1. Redis多服务器方案
互联网“三高”架构:
- 高并发
- 高性能
- 高可用
Redis多服务器方案有3种机制:master-slave、sentinel、cluster
1.1. 主从服务器
主从模式的结构是一台redis服务器负责数据写入,称为master,其他的redis服务器负责读数据,称为slave。 主从模式要解决的一个问题是master和slave之间的数据同步。
优点:
- 读写分离:master负责写,slave负责读
- 负载均衡
- 故障恢复:当master出现问题,slave可以变成master继续维持服务,实现故障快速恢复。
- 数据备份:多个slave实现数据热备份
1.1.1. 主从复制
主从复制主要分为以下几个过程:
- 建立关系
slaveof ip port:尝试建立当前服务器和远程服务器之间的master-slave关系。(此命令在Redis5开始被弃用,取而代之的是replicaof)。
slaveof执行后,slave服务器会保存master的ip和port,且master上的数据会同步到slave。 也可以在conf文件中配置这一命令,则启动后会自动执行。 - 数据同步
master和slave之间的数据同步分为全量复制和增量复制。
- 全量复制:将master的数据库数据以rdb文件形式发送给slave,slave加载rdb中的数据完成全量复制
- 增量复制:master将命令缓冲区中的命令发送给slave完成数据复制。
每次redis服务器启动后都会生成一个runid用来标识服务器。在进行主从同步时,slave将自己的runid和offset发送给master,如果master发现自己没有这个runid或者offset不在复制缓冲区内,执行全量复制。否则进行增量复制,假设slave发送过来的offset为offset1,master记录的offset为offset2,则master会重发offset1到offset2之间的复制缓冲区字节。
-
命令传播
心跳机制:在命令传播阶段,从服务器以每秒1次的频率向主服务器发送指令:
REPLCONF ACK <replication_offset>,replication_offset是当前slave的复制偏移量。心跳机制的主要作用有3个:
- 检测主从服务器的网络连接状态
如果master超过1s没有收到某个slave发送过来的replconf ack命令,证明master和slave之间的连接出问题了。
在master客户端执行info replication,可以看到slave的相关信息,其中有个属性为lag,这个值代表那个slave上一次向master发送replconf ack命令距离现在过了多久。lag的值正常为0或1,代表1s内收到了,如果大于1,证明master和slave之间的连接出故障了。 - 辅助实现min-slaves
redis的min-slaves-to-write和min-slaves-max-lag两个选项可以防止主服务器在不安全的情况下执行写入数据命令。 例如,在conf文件中配置:min-slaves-to-write 3和min-slaves-max-lag 10,那么在slave的数量小于3个或者3个slave的lag值都大于等于10s时,master会拒绝执行数据写入操作。 - 检测命令丢失
如果因为网络故障,master发送给slave的命令丢失,当slave向master发送
REPLCONF ACK命令时,master会发现从服务器当前的offset小于自己的offset,则会从复制积压缓冲区找到缺失的数据并重发给slave。
- 检测主从服务器的网络连接状态
注意:master向slave补发缺失数据和增量复制原理非常相似,区别在于,补发缺失数据是在主从服务器不断线的情况下执行,而增量复制是在主从服务器断线并重连之后执行。
1.2. 哨兵
主从切换:redis哨兵的作用主要是监控主从服务器,当master宕机,哨兵集群会从该master的所属slaves中选举一个slave成为master,并通知其他slave修改配置文件(如slaveof命令将会绑定新的master),达到高可用性。
redis-sentinel 配置文件:开启一个哨兵实例。
多个redis哨兵之间可以互相发现。
1.2.1. 工作原理
哨兵实现主从切换主要有3个阶段:
- 监控
- 通知
- 故障转移
1.3. 集群
1.3.1. 概念
集群(cluster)是Redis提供的分布式数据库方案,集群通过分片来进行数据共享,并提供复制和故障转移功能。
redis集群对于数据存储的实现方案是:将数据逻辑存储空间为成了16384个slots。在集群创建时,添加的节点一部分自动成为master,一部分成为slave,默认所有的slots在master上均分,slave不会被分配slots,它们的数据来自master的同步。
集群中每一个节点都会保存一份配置,它包含集群中所有节点状态信息的集合,master和slave都会有这份配置。
当redis某个master接收到一个写入key的命令,会通过哈希计算出key应该放在哪个slot中,如果slot在自己的存储空间,直接存入,否则通知客户端转向那个slot所在的master节点进行存储,因此一个key在集群中存储成功最多经过2个master节点。
1.3.2. 集群操作
1.3.2.1. 搭建集群
- 配置redis.conf文件,主要配置以下选项:
#集群模式开启,让实例能被加入集群 cluster-enabled yes #节点配置文件,和redis启动配置文件不同,它由集群节点自动维护 cluster-config-file 文件名 #节点最长失联时间,单位为ms cluster-node-timeout 时间 - 启动多个redis-server
当conf配置cluster开启后,server进程名将有[cluster]标识,但此时节点之间还未加入到集群中,还不能互相通信。 -
将redis-server添加到集群并启动
redis5以前需要安装ruby环境并执行redis/src下的redis-trib.rb脚本才能创建集群,redis5以后可以通过redis-cli直接创建集群,命令如下:redis-cli --cluster create 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 --cluster-replicas 1解释:
--cluster-replicas 1表示master和slave是一对一的关系,一个master拥有一个slave
如果命令执行成功,会输出格式如下的信息:
>>> Performing hash slots allocation on 6 nodes... Master[0] -> Slots 0 - 5460 Master[1] -> Slots 5461 - 10922 Master[2] -> Slots 10923 - 16383 Adding replica 127.0.0.1:6383 to 127.0.0.1:6379 Adding replica 127.0.0.1:6384 to 127.0.0.1:6380 Adding replica 127.0.0.1:6382 to 127.0.0.1:6381 >>> Trying to optimize slaves allocation for anti-affinity [WARNING] Some slaves are in the same host as their master M: 3edbcc5e6dc7c7779c4b1abc193a26c28e082333 127.0.0.1:6379 slots:[0-5460] (5461 slots) master M: 7a35ae4bcfe53b6d4e80a1e0d7fa517f82fff099 127.0.0.1:6380 slots:[5461-10922] (5462 slots) master M: e49d1699a21a1f3d65a092de546d2e2cda8d7936 127.0.0.1:6381 slots:[10923-16383] (5461 slots) master S: e0e7e7fa799b04b7f9b9883113a061803c8084db 127.0.0.1:6382 replicates e49d1699a21a1f3d65a092de546d2e2cda8d7936 S: 6ba92ec070dc6d41317bcad64dc041ac13fafd91 127.0.0.1:6383 replicates 3edbcc5e6dc7c7779c4b1abc193a26c28e082333 S: d7a3221bd75c2ee0e31d7b4b503293960b744c54 127.0.0.1:6384 replicates 7a35ae4bcfe53b6d4e80a1e0d7fa517f82fff099 Can I set the above configuration? (type 'yes' to accept): yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join . >>> Performing Cluster Check (using node 127.0.0.1:6379) M: 3edbcc5e6dc7c7779c4b1abc193a26c28e082333 127.0.0.1:6379 slots:[0-5460] (5461 slots) master 1 additional replica(s) M: e49d1699a21a1f3d65a092de546d2e2cda8d7936 127.0.0.1:6381 slots:[10923-16383] (5461 slots) master 1 additional replica(s) M: 7a35ae4bcfe53b6d4e80a1e0d7fa517f82fff099 127.0.0.1:6380 slots:[5461-10922] (5462 slots) master 1 additional replica(s) S: d7a3221bd75c2ee0e31d7b4b503293960b744c54 127.0.0.1:6384 slots: (0 slots) slave replicates 7a35ae4bcfe53b6d4e80a1e0d7fa517f82fff099 S: e0e7e7fa799b04b7f9b9883113a061803c8084db 127.0.0.1:6382 slots: (0 slots) slave replicates e49d1699a21a1f3d65a092de546d2e2cda8d7936 S: 6ba92ec070dc6d41317bcad64dc041ac13fafd91 127.0.0.1:6383 slots: (0 slots) slave replicates 3edbcc5e6dc7c7779c4b1abc193a26c28e082333 [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.
1.3.2.2. 客户端连接集群
redis -c -p 端口号:以cluster模式启动客户端,当set一个key,如果计算出来的slot不在本节点中,会自动重定向到slot所在的节点并存入,重定向以后,客户端和原来那个节点的连接断开,和slot所在节点连接,后面的操作也是如此。
如下图所示:
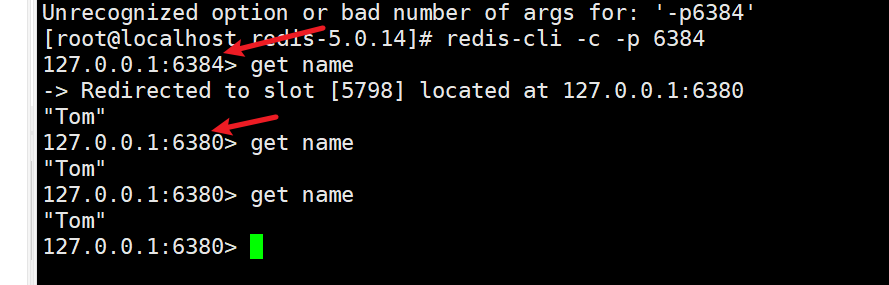
1.3.3. 集群性质
- 当master宕机,它的所属slave会选出一个作为新的master并分配slot,因此,集群本身具备了哨兵的作用。
2. 企业级方案
2.1. 缓存预热
缓存预热:系统启动前,提前将相关的数据加载到redis,避免大量用户请求查询关系型数据库造成巨大压力。
2.2. 缓存雪崩
redis大量的key集中过期,导致redis查询请求不命中转而查询数据库导致压力剧增甚至集群崩溃。
解决方案除了对redis进行运行监控以外,避免大量的key设置相同的有效期,“稀释”keys的过期。
2.3. 缓存击穿
某个热点key过期,大量请求查询数据库导致数据库压力剧增。
解决方案除了对redis进行运行监控以外,可以适时调整热点key的有效期。
2.4. 缓存穿透
大量非法url请求redis中不存在的key,每次查询数据库造成压力剧增,属恶意攻击。
解决方案除了对redis的运行监控,可以在查询前对url或key的合法性做检测,配合防火墙使用。