- 1. 概念
- 2. JVM结构
参考手册:https://docs.oracle.com/javase/specs/jvms/se8/html/
1. 概念
JVM,Java Virtual Machine,Java虚拟机,是Java语言二进制字节码的运行环境。 JVM只是一套规范,很多公司和组织都遵循这个规范实现了不同的JVM,目前,使用最广泛的JVM是HotSpot JVM。
1.1. JVM、JRE、JDK的关系
- JRE=JVM+基础类库
- JDK=JRE+编译工具
1.2. JVM的作用和规范
JVM 执行以下操作:
- Loads code
- Verifies code
- Executes code
- Provides runtime environment
JVM 提供了以下内容的定义:
- Memory area
- Class file format
- Register set
- Garbage-collected heap
- Fatal error reporting etc.
2. JVM结构
JVM的内部结构包括类加载器、内存区域、执行引擎等。
示意图如下:
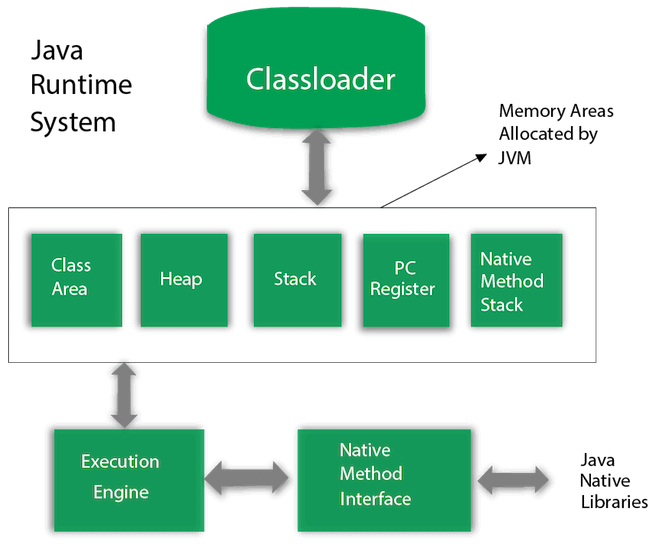
2.1. JVM内存区域(Memory Area)
JVM内存结构示意图如下:
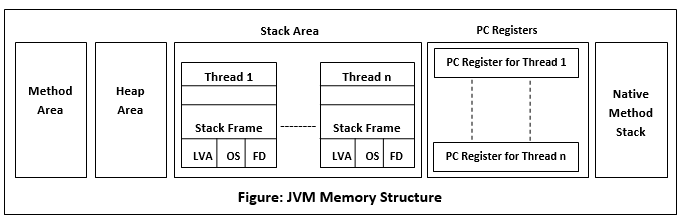
2.1.1. 程序计数器
Program Counter(PC,程序计数器),程序计数器包含当前线程正在执行的JVM指令的地址。字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
如果当前执行的是native方法,则程序计数器中的值是未定义的。
特点:
- PC是线程私有的,每个线程都有自己的PC,每次创建新的线程都会创建一个新的程序计数器,线程结束程序计数器被销毁。
- 程序计数器是JVM内存区域中唯一没有OOM(Out Of Memory)问题的内存区域,因为存储在程序计数器中的数据所占用的空间大小不会随着程序的执行而改变。
2.1.2. JVM Stacks
Java虚拟机栈是JVM为每个线程分配的内存空间。
- 每个栈由若干个栈帧(frames)组成,每一个栈帧对应一个方法调用所占用的内存。
- 每个线程都有一个私有的栈,和线程同时创建。
- 当方法被调用会创建一个栈帧,当方法调用结束销毁栈帧。
2.1.2.1. 栈内存溢出
栈内存溢出是指栈的内存超过了JVM分配的栈空间内存。
栈内存溢出发生的原因:
- 栈帧过多:常见的发生原因是过深的递归调用。
- 栈帧过大
2.1.2.2. 栈大小设置
使用java -Xss大小来设置栈的大小,其中,大小的单位可以是B、KB、MB、GB,
形式分别为:-Xss1、-Xss1K、-Xss1M、-Xss1G。
2.1.2.3. 线程问题诊断
- CPU占用过高,例如死循环等情况。
- CPU占用正常但程序卡住无法正常执行,例如发生死锁等情况。
当代码运行发生问题时,debug定位问题不是很方便,尤其是在多线程情况下,这时可以通过操作系统和Java本身提供的程序定位问题所在。
在Linux系统上:
top:查看进程以及系统资源的占用情况,动态变化。ps -H -eo pid,tid,%cpu:查看所有进程和进程下的线程的pid、tid和cpu占用,结果是一个快照,是静态的。- 对于CPU占用率过高的情况,当我们利用linux命令定位到进程id(pid)和线程id(tid),然后利用
jstack pid可以定位到问题线程和代码行。 - 当发生死锁,
jstack pid可以直接发现死锁。
tips:
ps命令显示的进程号(tid)是十进制,jstack中有两个进程号:
- tid:JVM中的进程号
- nid:系统中的进程号,以十六进制显示。
即ps命令的进程号和jstack命令输出结果中的nid是相同的,但前者是十进制,后者是十六进制。linux有现成的命令可以将十进制以十六进制显示:printf "%x" 十进制整数。
2.1.3. 本地方法栈(Native Method Stacks)
给native方法执行提供内存空间
2.1.4. 堆(Heap)
堆是所有JVM线程共享的内存区域,所有的class实例和数组都在堆中分配内存。
特点:
- JVM启动时创建堆
- 所有JVM线程共享
- 内存由垃圾收集器回收
2.1.4.1. 设置堆内存大小
-Xmx<size>:设置最大的Java堆大小-Xms<size>:设置初始的Java堆大小 size的单位默认是byte,可以显示设置为k、m、g
tips:命令java -X可以显示所有参数的用法。
2.1.4.2. jmap
map 打印给定进程、核心文件或远程调试服务器的共享对象内存映射或堆内存细节。如果给定的进程在64位 VM 上运行,您可能需要指定 -j-d64选项,例如:
jmap -J-d64 -heap pid
查看pid可以用操作系统命令,也可以使用jps快捷查看。
2.1.5. 方法区(Method Area)
方法区在JVM线程间共享,用来存储每个类的结构,比如运行时常量池、字段和方法数据以及普通方法和构造方法的代码,以及用于class的special methods、实例初始化和接口初始化的信息。
- 方法区在JVM启动时创建
- 方法区在逻辑上是堆的一部分,但简单的实现也许不会对其进行垃圾回收。
- Method Area是一种规范,不同的JVM对其有不同的实现。对于Hotspot,Java8以前,对方法区的实现的区域称作永久代,是JVM堆的一部分。Java8移除了永久代,用了元空间(Metaspace)作为方法区的新的实现,并且Metaspace是在本地内存中分配而不是在JVM堆中分配。
方法区在规范上存在内存溢出的问题,但Java8的方法区实现即元空间在本地内存中分配,一般不会出现内存溢出问题。
2.1.5.1. 常量池
类文件将其所有的符号引用保存在一个地方,即常量池。每个类文件都有一个常量池,由 Java 虚拟机加载的每个类或接口都有一个称为运行时常量池的常量池的内部版本。运行时常量池是一种特定于实现的数据结构,映射到类文件中的常量池。
2.1.5.1.1. StringTable
StringTable是字符串常量池,用来存放字符串常量,逻辑上属于常量池的一部分,数据结构为哈希表。
Java7中将StringTable从方法区移到了堆中。Java8保留了这一更改,并且Java8将方法区(除StringTable外)的实现用元空间替代了永久代,并移到本地内存中。
string table相关参数:
- 打印spring table统计数据:
-XX:+PrintStringTableStatistics
示例结果:SymbolTable statistics: Number of buckets : 20011 = 160088 bytes, avg 8.000 Number of entries : 16171 = 388104 bytes, avg 24.000 Number of literals : 16171 = 665648 bytes, avg 41.163 Total footprint : = 1213840 bytes Average bucket size : 0.808 Variance of bucket size : 0.806 Std. dev. of bucket size: 0.898 Maximum bucket size : 6 StringTable statistics: Number of buckets : 1009 = 8072 bytes, avg 8.000 Number of entries : 482773 = 11586552 bytes, avg 24.000 Number of literals : 482773 = 29826096 bytes, avg 61.781 Total footprint : = 41420720 bytes Average bucket size : 478.467 Variance of bucket size : 432.071 Std. dev. of bucket size: 20.786 Maximum bucket size : 547 - 调整string table的桶数量(buckets):
-XX:StringTableSize=1009
string table的桶数量越大,哈希冲突越少,每个桶存储的元素越少,存储速度和查找速度越快。
2.1.6. 垃圾回收(Garbage Collection)
2.1.6.1. 如何判断对象可以回收
- 引用计数法
- 可达性分析法 Hotspot采用的是可达性分析法来判断对象是否可被回收。 GC Roots是JVM中不会被回收的对象。
GC Roots指堆外直接可达的对象,包括:
- Active threads
- Static variables
- Local variables (accessible via stack of a thread)
- JNI references
2.1.6.1.1. 五种引用
java.lang.ref包提供引用对象类,利用这些类可以和GC实现有限的交互,避免了手动System.gc()执行的Full GC。
参考:https://docs.oracle.com/javase/7/docs/api/java/lang/ref/package-summary.html
-
强引用 在Java中,使用
new创建的对象直接复制给某个变量叫做强引用,这种引用指向的对象,JVM即使抛出OOM也不会回收。 - 软引用(SoftReference)
- 弱引用(WeakReference)
- 虚幻引用(PhantomReference)
- 终结器引用
由这几种引用衍生出对象的几种可达性状态:
- An object is strongly reachable if it can be reached by some thread without traversing any reference objects. A newly-created object is strongly reachable by the thread that created it.
- An object is softly reachable if it is not strongly reachable but can be reached by traversing a soft reference.
- An object is weakly reachable if it is neither strongly nor softly reachable but can be reached by traversing a weak reference. When the weak references to a weakly-reachable object are cleared, the object becomes eligible for finalization.
- An object is phantom reachable if it is neither strongly, softly, nor weakly reachable, it has been finalized, and some phantom reference refers to it.
- Finally, an object is unreachable, and therefore eligible for reclamation, when it is not reachable in any of the above ways.
2.1.6.2. 垃圾回收算法
- 标记-清除 对不可达对象进行标记,释放内存,会产生内存碎片的问题。
- 标记-整理 对不可达对象进行标记,释放内存,并且“压缩”内存空间,可解决内存碎片问题,但整理过程需要耗费额外的时间(复制对象、更新引用)。
- 标记-复制
1969年Fenichel提出了一种称为“半区复制”(Semispace Copying)的垃圾收集算法,它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。如果内存中多数对象都是存活的,这种算法将会产生大量的内存间复制的开销,但对于多数对象都是可回收的情况,算法需要复制的就是占少数的存活对象,而且每次都是针对整个半区进行内存回收,分配内存时也就不用考虑有空间碎片的复杂情况,只要移动堆顶指针,按顺序分配即可。这样实现简单,运行高效,不过其缺陷也显而易见,这种复制回收算法的代价是将可用内存缩小为了原来的一半,空间浪费未免太多了一点。
2.1.6.3. 分代垃圾收集
Hotspot为了提高垃圾回收的效率,将heap分成了两个区域:新生代(Young Generation)和老年代(Old Generation)。 其中,新生代又分为三个区域:Eden和2个Survivor区——From-Space和To-Space。 Eden和from space、to space默认的比例是8:1:1。
- Minor GC
在新生代上进行的垃圾收集叫minor gc,它使用的收集算法是上面的标记-复制法。
上面提到标记-复制法需要足够的内存空间,并且在存储对象的时候有一部分是始终为空的,在垃圾收集时,存储了对象的那一部分内存会和空的那部分交换位置。
hotspot对这种方法做了改进。 首先,JVM中新创建的对象都是在Eden区,如果创建对象时Eden区可用内存不够则会触发Minor GC,它的过程是这样的:- 将Eden和From-Space中的可达对象复制到To-Space,且对象的age增加1,然后交换From和To的位置(可以理解为From和To两个内存指针交换,这样保证在没有触发minor gc时幸存空间To始终是空的),一次minor gc后,From-Space存储了gc前的可达对象,Eden区和To-Space则都是空的。
- 每次minor gc被触发,可达对象的age都会加1。如果From区域里面某个对象的age已经达到15,则在下一次minor gc时,对象会进入老年代。
- Full GC 对整个heap进行垃圾收集,即包括新生代和老年代。老年代使用的垃圾收集算法和新生代不同,是标记-整理法。
由于涉及到对象的复制和引用更新问题,GC在执行时会引起全局停顿——STW(stop the world),即所有用户线程都被暂停,等待垃圾收集线程执行完毕。
2.1.6.4. 垃圾收集器
- 串行收集器
- 解释:单个垃圾收集器线程进行垃圾收集,在垃圾收集时,JVM中非垃圾收集线程都要停止,即会发生STW。
- 开启
JVM options:-XX:+UseSerialGC,新生代使用Serial收集器,老年代使用SerialOld垃圾收集器。 对于新生代,使用标记-复制法,老年代使用标记-整理法。 - 特点:单个垃圾回收线程,Client模式默认的垃圾收集器。
- 并行收集器(吞吐量优先)
-
解释:多个垃圾收集线程并行执行。
- 参数选项
-XX:+UseParalleGC:新生代和老年代都使用Parallel收集器(新生代使用 parallel scavenge garbage collector)-XX:+UseParalleOldGC:老年代使用Paralle收集器,默认关闭,当UseParalleGC开启时自动开启。-XX:+UseParNewGC:新生代使用多个垃圾收集线程,默认关闭,除非使用-XX:+UseConcMarkSweepGC,则会自动开启。
- 特点:多个垃圾回收线程并行执行,吞吐量优先,适合大量数据运算的场景。
-
- CMS
- 解释
老年代使用的一种垃圾收集器,Concurrent-Mark-Sweep,使用标记-清除法,没有对内存压缩,有内存碎片的问题,如果内存碎片到达一定程度,会使用SerialOld收集器对老年代进行清理。 - 参数选项
-XX:+UseConcMarkSweepGC:对老年代使用CMS收集器
- 特点
单次执行时间短,适合对响应时间要求高的场景。 - 执行过程
- 初始标记:仅仅标记GC Roots能直接关联的对象,速度快
- 并发标记:进行GC Roots Tracing
- 重新标记:修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,,这个阶段的停顿时间一般会比初始标记阶段稍长一些,但远比并发标记的时间短。
- 并发清除:清除不可达对象 由于整个过程中耗时最长的并发标记和并发清除过程收集器线程都可以与用户线程一起工作,所以,从总体上来说,CMS收集器的内存回收过程是与用户线程一起并发执行的。
- 解释
- G1
在G1之前的其他收集器进行收集的范围都是整个新生代或者老年代,而G1不再是这样。使用G1收集器时,Java堆的内存布局就与其他收集器有很大差别,它将整个Java堆划分为多个大小相等的独立区域(Region),虽然还保留有新生代和老年代的概念,但新生代和老年代不再是物理隔离的了,它们都是一部分Region(不需要连续)的集合。
- 解释 Garbage First收集器。
- 参数选项
-XX:+UseG1GC:使用G1垃圾收集器进行垃圾收集
- 特点
- 同时注重低延迟和吞吐量
2.2. 解释器和JIT
- 解释器:将class字节码解释成机器码,每次都要解释—>执行
- JIT:将class字节码编译成机器码并缓存,下次执行相同的字节码指令不需要解释(意味着这些字节码是热点代码),JIT分为C1(Client Compile)、C2(Server Compile)
2.3. JVM运行期优化
2.3.1. C2编译器优化
通过逃逸分析进行优化,包括:
- 同步消除:如果确定一个对象不会被其他线程访问到,消除该对象的同步锁。
- 标量替换:不在堆中创建对象,将对象拆分成基本数据类型,在栈上分配。