1. SQL执行分析
1.1. EXPLAIN
EXPLAIN关键字和SELECT, DELETE, INSERT, REPLACE, UPDATE语句一起使用,结果是来自优化器的关于语句执行计划的信息。也就是说,MySQL 解释了它将如何处理这个语句,包括关于如何联接表以及以何种顺序联接表的信息。
参考:https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain-extra-information
1.1.1. 语法
{EXPLAIN | DESCRIBE | DESC}
tbl_name [col_name | wild]
{EXPLAIN | DESCRIBE | DESC}
[explain_type]
{explainable_stmt | FOR CONNECTION connection_id}
explain_type: {
EXTENDED
| PARTITIONS
| FORMAT = format_name
}
format_name: {
TRADITIONAL
| JSON
}
explainable_stmt: {
SELECT statement
| DELETE statement
| INSERT statement
| REPLACE statement
| UPDATE statement
}
1.1.2. 输出分析
| COLUMN | 含义 |
|---|---|
| id | The SELECT identifier |
| select_type | The SELECT type |
| table | The table for the output row |
| partitions | The matching partitions |
| type | The join type |
| possible_keys | The possible indexes to choose |
| key | The index actually chosen |
| key_len | The length of the chosen key |
| ref | The columns compared to the index |
| rows | Estimate of rows to be examined |
| filtered | Percentage of rows filtered by table condition |
| Extra | Additional information |
1.1.2.1. id
SELECT 标识符。这是查询中 SELECT 的顺序号。
1.1.2.2. select_type
| select_type Value | Meaning |
|---|---|
| SIMPLE | Simple SELECT (not using UNION or subqueries) |
| PRIMARY | Outermost SELECT |
| UNION | Second or later SELECT statement in a UNION |
| DEPENDENT UNION | Second or later SELECT statement in a UNION, dependent on outer query |
| UNION RESULT | Result of a UNION. |
| SUBQUERY | First SELECT in subquery |
| DEPENDENT SUBQUERY | First SELECT in subquery, dependent on outer query |
| DERIVED | Derived table |
| MATERIALIZED | Materialized subquery |
| UNCACHEABLE SUBQUERY | A subquery for which the result cannot be cached and must be re-evaluated for each row of the outer query |
| UNCACHEABLE UNION | The second or later select in a UNION that belongs to an uncacheable subquery (see UNCACHEABLE SUBQUERY) |
分析select_type:
-- SIMPLE
EXPLAIN select *from dept D JOIN emp E ON D.deptno=E.deptno;
-- PRIMARY
EXPLAIN select *from emp WHERE deptno=(SELECT deptno FROM dept WHERE dname='SALES');
-- SUBQUERY
EXPLAIN select *from emp WHERE deptno=(SELECT deptno FROM dept WHERE dname='SALES');
-- DERIVED
EXPLAIN select *from (select *from emp LIMIT 5 )t1;
-- UNION
EXPLAIN (SELECT *FROM emp WHERE ename='JAMES') UNION (SELECT *FROM emp WHERE ename='SMITH');
1.1.2.3. type
type列描述操作的表是如何连接的,是explain中非常重要的结果列。 type从最佳类型到最差类型排序为:
- system
- const
- eq_ref
- ref
- fulltext
- ref_or_null
- index_merge
- unique_subquery
- index_subquery
- range
- index
- ALL
# 分析type
-- const
EXPLAIN select *from emp WHERE empno=7369;
-- ALL
EXPLAIN select *from emp WHERE ename='SMITH';
-- range
EXPLAIN select *from emp WHERE empno>1000;
1.1.2.4. table
当前操作的表的名称,如果给定别名则为别名
1.1.2.5. possible_keys
当前操作的表可能用的索引
1.1.2.6. key
实际操作用到的索引
1.1.2.7. key_len
The length of the chosen key
1.1.2.8. ref
1.1.2.9. rows
扫描的行数量
1.1.2.10. filtered
1.1.2.11. Extra
额外信息,比较重要的有:
- Using filesort:排序字段没有索引,使用了文件排序
1.2. SHOW PROFILE/PROFILES
SHOW PROFILE 和 SHOW PROFILES 语句显示分析信息,指示在当前会话过程中执行的语句的资源使用情况。
执行SET profiling = 1开启SQL执行资源收集,profile是一个会话变量。
SHOW PROFILES 显示发送到服务器的最新语句的列表。列表的大小由 profil_history _ size 会话变量控制,该会话变量的默认值为15。最大值为100。将该值设置为0具有禁用分析的实际效果。
1.2.1. SHOW PROFILE语法
SHOW PROFILE [type [, type] ... ]
[FOR QUERY n]
[LIMIT row_count [OFFSET offset]]
type: {
ALL
| BLOCK IO
| CONTEXT SWITCHES
| CPU
| IPC
| MEMORY
| PAGE FAULTS
| SOURCE
| SWAPS
}
Showprofile 显示有关单个语句的详细信息。如果没有 forqueryn 子句,则输出属于最近执行的语句。如果包含 FOR QUERY n,则 SHOW PROFILE 显示语句 n 的信息。N 的值对应于 SHOW PROFILES 显示的 Query _ id 值。
参考:https://dev.mysql.com/doc/refman/5.7/en/show-profile.html
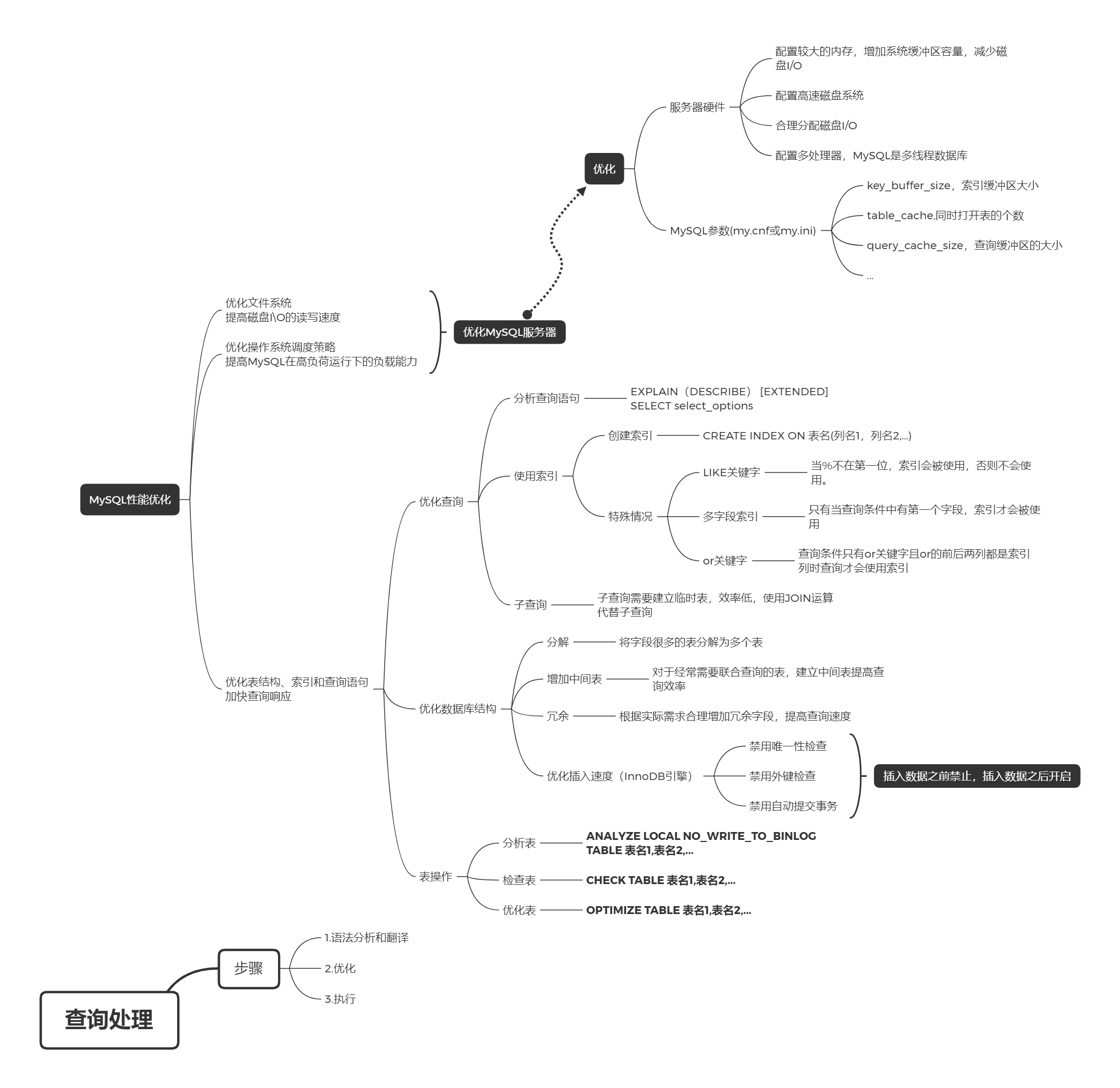
2. 优化
2.1. 索引
2.1.1. 索引失效
2.1.1.1. 最左前缀原则
最左前缀原则:对于在多个字段上建立的联合索引,比如idx_name(col1,col2,col3),只有当查询条件包含(col)或(col1,col2)或(col1,col2,col3)时,在查询时才会使用索引。
如何理解? 索引的数据结构是B+树,建立索引的字段是有序排列的,当建立一个联合索引,先按照第一个列有序排列,当第一个列的值相等再按照第二个字段排列,…… 当第一个字段不出现在条件中,就无法通过有序的联合索引查找,因为其他的字段不是有序排列的,这种情况下只能全表扫描。
2.1.1.2. 范围查询右边的索引列索引失效
2.1.1.3. 在索引列上做计算索引失效
2.1.1.4. 字符串索引列查询条件不加’索引失效
2.1.1.5. 查询条件为or且字段不同索引失效
2.1.1.6. %开头的模糊查询
当查询字段为索引字段且做模糊查询,以%开头:
- 如果select字段为索引字段,会直接使用索引查询。
- 如果select字段不是索引字段,会全表扫描。
2.1.1.7. null判断
mysql根据Null值离散度决定使用or不使用索引。
2.1.1.8. IN/NOT IN
对于普通索引,IN运算索引生效,NOT IN运算索引不生效。
2.1.1.9. 单列索引和多列索引
如果表有多个单列普通索引,那这些索引列出现在查询条件中时,只会有一个索引生效,mysql优化器选择最优的索引列来查询。 所以一般用多列索引代替多个单列索引。
2.2. SQL语句
2.2.1. 格式化文件导入
再进行格式化数据文件导入mysql时,通过这两个操作可以加快数据导入速度:
- 尽量保证主键有序,能大大加快插入速度。
- 关闭唯一性校验:
SET UNIQUE_CHECKS=0
2.2.1.1. 例子
user.data文件(在Windows系统上创建,行末为\r\n):
1,"Mike","&^&HDSA"
2,"Mike","&^&HDSA"
3,"Mike","&^&HDSA"
4,"Mike","&^&HDSA"
5,"Mike","&^&HDSA"
6,"Mike","&^&HDSA"
7,"Mike","&^&HDSA"
8,"Mike","&^&HDSA"
9,"Mike","&^&HDSA"
10,"Mike","&^&HDSA"
11,"Mike","&^&HDSA"
12,"Mike","&^&HDSA"
13,"Mike","&^&HDSA"
导入到MySQL:
set GLOBAL local_infile=1;
load data local infile "D:\\MySQL\\data\\user.data"
INTO TABLE user
fields
TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\r\n'
order by优化
order by的字段尽量加上索引,如有多个排序字段,最好建立联合索引,且多个排序字段的顺序尽量和联合索引中的顺序一致。